
May 16, 2022
Migration is the Hard Part
By Martin EveIn scholarly communications, when we talk about “vendor lock-in”, what we actually mean is the difficulty (or seeming impossibility) of moving from one platform to another: “migrations.” This can be technical. Platforms may not provide data export in a standardized format or there may be no tooling to complete the migration automatically. Lock-in can also be social, though. If the terms of the platform take coercive IP ownership of the data put into the platform, then it can also become impossible to move from one space to another.
Various aspects of the Next Generation Library Publishing (NGLP) project, on which I have been working, have striven towards fixing the friction of migration. On the first front, the project is built on cooperation and flexibility. We should not underestimate the power of agreements between vendors. NGLP project partners are working together to ensure that our contracts and terms are not restrictive on what libraries can do with their data.
We are also working on the technical side, though. In particular, the Web Delivery Platform from NGLP and Janeway submission systems sit in harmony with one another to present an end-to-end document management and display mechanism. For this to be of any use, though, we have had to develop a series of tools to help with migration (primarily from Bepress systems).
The primary background software output from the project on which I have worked is the NGLP import tool: a command-line based tool for mass-importing electronic theses and dissertations to the WDP system. The code for the importer is open source under the AGPL-3.0 license.
How does it all work? The importer takes a series of Bepress public URLs. It first translates these into the standard Bepress XML export URL, which gives us the background metadata for the page. For instance, the dissertation at
https://scholarworks.umass.edu/masters_theses_2/752/
has an export URL of
Once we have this XML, we can start parsing it. The challenge, though, is that every single Bepress install appears free to use fields differently. There is no real harmonization between these systems, so our importers have to be flexible enough to understand a variety of potential inputs. Ideally, we’d specify which fields libraries should use, but this simply isn’t practicable in the real world. We therefore built an engine that allows for dynamic field creation, meaning that future updates will be able to be fast and flexible. For instance, see the following code block:
# a list of fields to extract from Bepress metadata
field_list = [‘degree_name’, ‘award_month’, ‘degree_year’, r’advisor\d*’, ‘publication_date’, ‘distribution_license’]
# a list of field mappings that map variables onto the final
# substitution values
field_mappings = OrderedDict()
field_mappings[‘degree_name’] = [‘degree_name’, ‘level’]
field_mappings[‘award_month’] = ‘award_month’
field_mappings[‘degree_year’] = [‘degree_year’, ‘publication_date’]
In this block, we first tell the engine that we want to pull out “degree_name”, “award_month”, “degree_year”, “advisor\d” (this means: “advisor” and then a number, so anything like “advisor1”, “advisor2” etc.), “publication_date”, and “distribution_license”. The second block then tells the engine what to do with these values. So the final variable “degree_year” for instance should be mapped either to “degree_year” if that exists or to “publication_date” if that’s all we have. The reason is that some systems use “degree_year”, while others use “publication_date”.
We also have a set of concatenation hooks to merge values together:
# concatenation hooks to merge values
concat_hooks = OrderedDict()
concat_hooks[‘advisor’] = [r’advisor\d*’]
concat_hooks[‘degree_year’] = [‘award_month’, ‘degree_year’
This code tells the engine that the final value of “advisor” should be all of the numerical values from “advisor1”, “advisor2” etc. up to “advisor9”. Similarly, the final value of “degree_year” should be the “award_month” jammed together with “degree_year”.
Once the engine has done its complex parsing, the interaction with the WDP begins. The WDP uses Keycloak for authentication, so you need a client secret key for each WDP realm that you are using. This key should support the password authentication type. A “gotcha” that we encountered, but that seemed tricky to replicate, was that I needed manually to change the password for each of the realms. The importer client supports the test-authorization method to ensure that the login system is working.
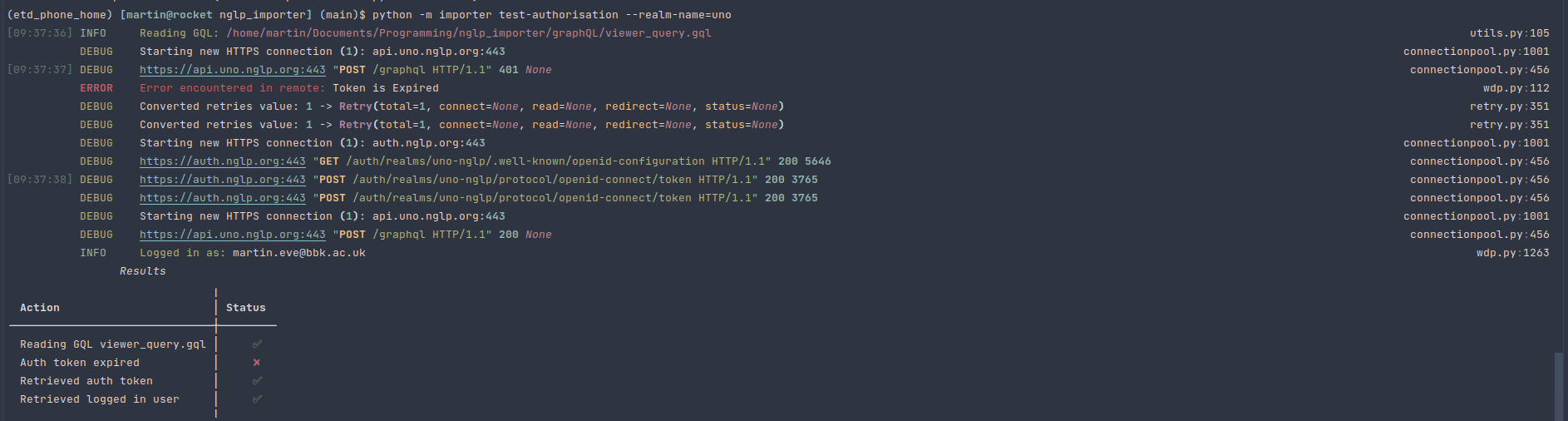
Figure 1: the client testing authentication and authorization
Once logged in, the client creates a copy of the artifact in the WDP. This is done using a GraphQL API, which allows for multiple calls and writes within a single request. There are lots of complexities to this, but essentially this gets the core data in.
The final piece of the puzzle is associating files with each WDP artifact. The WDP uses TUS and AWS S3 buckets to store files. TUS is a resumable file upload system that allows for chunked uploads (although–another “gotcha”–you can’t, with the S3 backend, use chunk sizes smaller than 5MB.) This allows us to migrate the PDFs from the original dissertations into the WDP.
Using this approach, we have managed to migrate several hundred electronic theses into the system in an automated fashion. Tooling like this reduces the overhead of migration, but requires a one-time effort to write and ongoing effort to maintain. Systems like the WDP, which homogenize display technologies from different systems, provide one way to ease migration pain while maintaining a known single interface.
But this is, I am afraid, the sad moral of the story: if we are going to liberate library publishing from for-profit enterprises with high barriers to exit, we need to resource migration activities. We can cement open practices for the future in open technologies and with community agreements. But to make it truly easy for people to move between systems at the moment remains a lot of work.
The next step of the NGLP project is to expand this interoperability and migration. Our vision is of a future environment where library publishers can move seamlessly between platforms, without the overhead of new software and without the challenges of lock-in. Stay tuned to hear more about the next phase of the project.
About the Next Generation Library Publishing Project
Educopia, California Digital Library (CDL), and Strategies for Open Science (Stratos), in close partnership with Confederation of Open Access Repositories (COAR), Janeway Systems, and Longleaf Services are working to advance and integrate open source publishing infrastructure to provide robust support for library publishing. The project’s purpose is to improve publishing pathways and choices for authors, editors, and readers through strengthening, integrating, and scaling up scholarly publishing infrastructure to support library publishers. In addition to developing interoperable publishing tools and workflows, our team is exploring how to create community hosting models that align explicitly and demonstratively with academic values. The project is generously funded by Arcadia, a charitable fund of Lisbet Rausing and Peter Baldwin.